

Pasarela de IA para gestión de tráfico de modelos LLM
La adopción de la Inteligencia Artificial Generativa ha dejado de ser una ventaja competitiva experimental para convertirse en un requisito operativo estándar. Sin embargo, a medida que las organizaciones integran Large Language Models (LLM) en sus flujos de trabajo, surge un desafío crítico que a menudo se pasa por alto en la fase de prototipado: la infraestructura subyacente. La conexión directa entre aplicaciones y proveedores de modelos genera un ecosistema frágil, costoso y difícil de auditar.
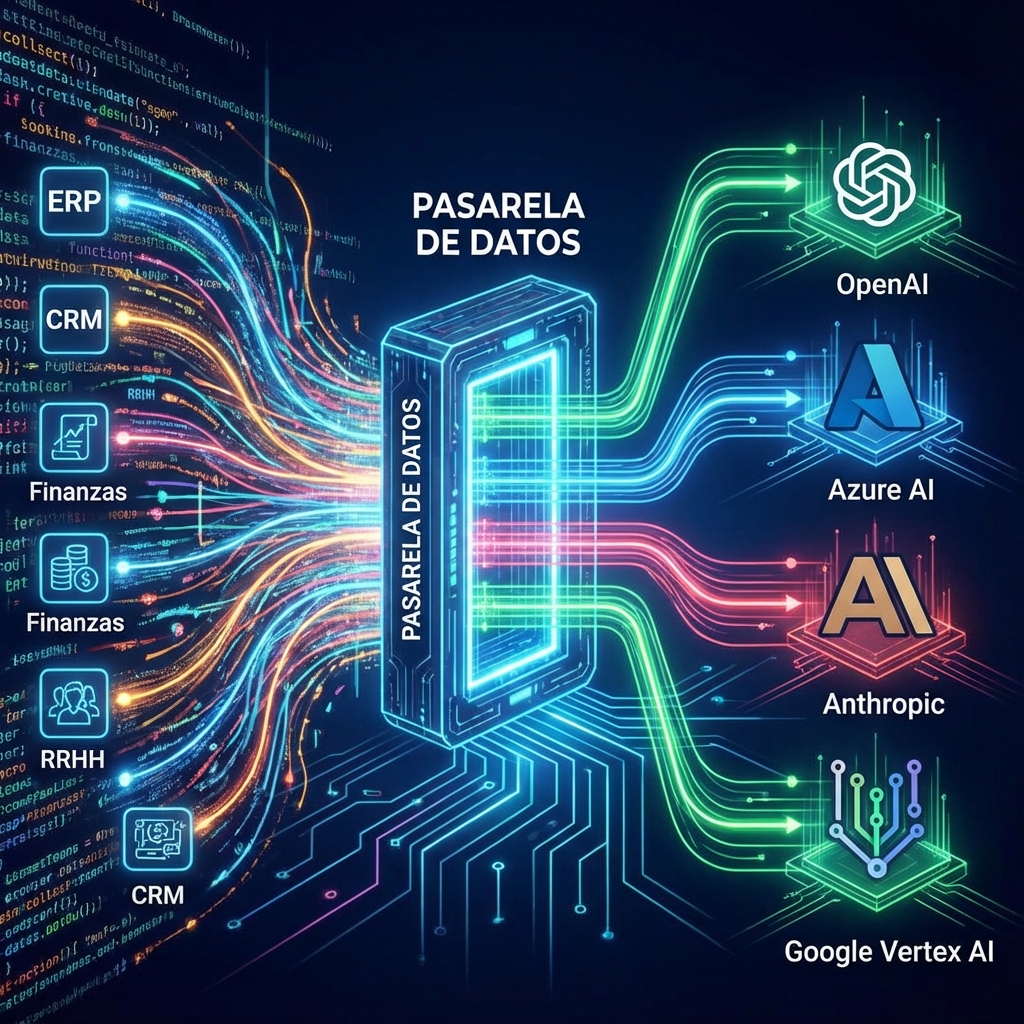
En este escenario, la implementación de una pasarela de IA para gestión de tráfico de modelos LLM se posiciona como la pieza angular de una estrategia tecnológica madura. No se trata simplemente de conectar una API; se trata de orquestar, asegurar y optimizar cada interacción que la empresa tiene con la inteligencia artificial. En Medina Core, entendemos que la escalabilidad real de la IA no depende solo de la potencia del modelo, sino de la inteligencia de la arquitectura que lo soporta.
¿Qué es una pasarela de IA para modelos LLM?
Una pasarela de IA, conocida técnicamente como AI Gateway, es un componente de middleware diseñado específicamente para actuar como intermediario único y centralizado entre las aplicaciones de una organización y los diversos proveedores de modelos de lenguaje (como GPT-4 de OpenAI, Claude de Anthropic, Llama de Meta o modelos alojados en infraestructura propia).
A diferencia de una conexión directa, donde cada equipo de desarrollo gestiona sus propias credenciales y lógicas de conexión, la pasarela de IA para gestión de tráfico de modelos LLM unifica estas interacciones. Funciona como un plano de control que abstrae la complejidad de los proveedores subyacentes, permitiendo a las empresas cambiar de modelo, gestionar costes y aplicar políticas de seguridad sin necesidad de reescribir el código de sus aplicaciones.
Arquitectura básica y flujo de peticiones
La arquitectura de una pasarela de IA se sitúa estratégicamente en el borde de la infraestructura de backend de la empresa. El flujo de una petición típica sigue un proceso estructurado y supervisado:
- Recepción de la solicitud: La aplicación interna (CRM, chatbot, herramienta de análisis) envía un prompt a la pasarela utilizando una API unificada y estandarizada.
- Procesamiento previo (Pre-processing): La pasarela analiza la solicitud. Aquí se verifica la autenticación, se comprueban los límites de velocidad (rate limits) y se escanea el contenido en busca de datos sensibles o inyecciones de prompts maliciosos.
- Enrutamiento inteligente: Basándose en reglas predefinidas (coste, latencia, complejidad de la tarea), la pasarela decide a qué modelo enviar la petición.
- Interacción con el proveedor: La pasarela traduce la solicitud al formato específico del proveedor seleccionado (OpenAI, Bedrock, Vertex AI) y la envía.
- Procesamiento posterior (Post-processing): Al recibir la respuesta del modelo, la pasarela la normaliza, registra las métricas de uso y la devuelve a la aplicación original.

Diferencias fundamentales entre un API Gateway tradicional y una pasarela de IA
Es un error común confundir un API Gateway estándar (como Kong o Apigee) con una pasarela diseñada para LLMs. Aunque comparten principios de enrutamiento, sus funciones divergen en la naturaleza del tráfico que gestionan:
- Gestión de Tokens vs. Peticiones: Un gateway tradicional mide el tráfico en peticiones por segundo (RPS). Una pasarela de IA debe gestionar y auditar el consumo de tokens (entrada y salida), que es la unidad real de coste y rendimiento en los LLMs.
- Streaming y Latencia Prolongada: Las respuestas de los LLMs pueden tardar segundos o minutos y a menudo se transmiten en tiempo real (streaming). Las pasarelas de IA están optimizadas para mantener estas conexiones abiertas y gestionar el backpressure de manera eficiente, algo que los gateways tradicionales suelen interrumpir por time-outs.
- Caché Semántico: Mientras que un caché tradicional almacena respuestas basándose en URLs exactas, una pasarela de IA utiliza caché semántico. Esto significa que puede identificar si una pregunta nueva es semánticamente idéntica a una anterior (aunque las palabras varíen ligeramente) y devolver la respuesta almacenada, ahorrando costes de computación y tiempo.
Beneficios estratégicos de la gestión de tráfico LLM
Implementar una pasarela de IA para gestión de tráfico de modelos LLM trasciende la mera cuestión técnica; es una decisión de negocio que impacta directamente en la cuenta de resultados y en la gestión del riesgo corporativo.
Optimización de costes y control granular de tokens
El modelo de precios de la IA generativa, basado en el pago por uso (pay-as-you-go), puede derivar en facturas astronómicas si no se supervisa. Una pasarela actúa como un auditor financiero en tiempo real:
- Políticas de Cuotas: Permite establecer límites de gasto diarios o mensuales por departamento, proyecto o incluso por usuario individual. Si un equipo de desarrollo agota su presupuesto de tokens, el sistema puede detener el servicio o degradarlo a un modelo más económico automáticamente.
- Arbitraje de Modelos: Para tareas sencillas (como resumir un email), no es necesario utilizar el modelo más potente y caro del mercado. La pasarela puede enrutar estas peticiones a modelos «ligeros» (como GPT-3.5 o Claude Haiku) y reservar los modelos de «razonamiento profundo» (como GPT-4 o Claude Opus) para tareas complejas, reduciendo la factura global drásticamente.
- Caché Inteligente: Al almacenar respuestas frecuentes, las organizaciones pueden reducir el volumen de llamadas a la API externa entre un 20% y un 40%, eliminando costes redundantes.
Seguridad, privacidad y cumplimiento (GDPR)
La fuga de propiedad intelectual y datos personales hacia servidores de terceros es la principal preocupación de los CISO (Chief Information Security Officers). La pasarela de IA funciona como un cortafuegos de aplicación para LLMs:
Mediante la implementación de guardrails o filtros de seguridad, el sistema puede detectar y ofuscar automáticamente Información de Identificación Personal (PII) —como correos electrónicos, números de tarjetas de crédito o DNI— antes de que el prompt salga del perímetro de la empresa. Esto es vital para cumplir con normativas estrictas como el GDPR en Europa.
Además, centralizar las claves de API (API Keys) en la pasarela elimina el riesgo de que estas credenciales queden expuestas en el código fuente de las aplicaciones cliente o en repositorios públicos, una vulnerabilidad de seguridad crítica y frecuente.
Balanceo de carga y alta disponibilidad multimodelo
La dependencia de un único proveedor de IA es un riesgo operativo. Las caídas de servicio en plataformas como OpenAI o Anthropic ocurren, y pueden paralizar operaciones críticas. Una gestión de tráfico eficiente mitiga este riesgo mediante estrategias de enrutamiento dinámico.
Si el proveedor principal experimenta latencia alta o errores de servidor (códigos 5xx), la pasarela puede redirigir automáticamente el tráfico a un proveedor secundario de respaldo (fallback) sin que el usuario final perciba la interrupción. Esta capacidad de conmutación garantiza la continuidad del negocio y ofrece una resiliencia que una integración directa no puede proporcionar.
Implementación técnica y observabilidad
Para los equipos de ingeniería, la pasarela de IA transforma una «caja negra» en un sistema transparente y medible. La observabilidad es la clave para iterar y mejorar los productos basados en IA.
Monitoreo de latencia y métricas de rendimiento en tiempo real
No se puede mejorar lo que no se mide. Una infraestructura robusta debe proporcionar un panel de control (dashboard) que visualice métricas críticas:
- Latencia P95 y P99: Entender cuánto tardan las respuestas en generarse para la mayoría de los usuarios, permitiendo detectar cuellos de botella.
- Tasa de errores: Identificación proactiva de fallos en los prompts o rechazos por parte de los proveedores.
- Análisis de sentimiento y calidad: Algunas pasarelas avanzadas permiten evaluar la calidad de las respuestas recibidas o el sentimiento de los usuarios, proporcionando feedback cualitativo además de cuantitativo.
Este nivel de detalle permite a los ingenieros ajustar los parámetros de los modelos (como la temperatura o el top_p) basándose en datos reales de uso, no en suposiciones.
Interoperabilidad: Integración con el stack tecnológico empresarial
Una pasarela de IA para gestión de tráfico de modelos LLM no debe ser una isla. Su valor se multiplica cuando se integra fluidamente con el ecosistema existente. Las soluciones líderes ofrecen SDKs compatibles con lenguajes populares (Python, Node.js, Go) y se conectan con plataformas de observabilidad estándar como Datadog, Prometheus o Grafana.
Asimismo, la capacidad de integrarse con sistemas de gestión de identidad (como Okta o Azure AD) asegura que el acceso a los recursos de IA esté alineado con las políticas corporativas de control de acceso basado en roles (RBAC).
El rol de la infraestructura de IA en la estrategia SEO
En Medina Core, sabemos que la tecnología y el marketing orgánico están intrínsecamente ligados. Una gestión de tráfico de IA eficiente tiene un impacto directo y potente en la capacidad de una empresa para ejecutar estrategias de SEO a gran escala.
La generación de contenidos programáticos o la asistencia en la redacción de artículos long-form requiere un flujo constante y fiable de interacciones con LLMs. Si la infraestructura falla o los costes se disparan, la estrategia de contenidos se detiene. Una pasarela optimizada permite:
- Escalabilidad de Contenidos: Generar miles de descripciones de productos o meta-etiquetas sin temor a bloqueos de API o facturas sorpresa, manteniendo la velocidad de publicación que exigen los motores de búsqueda.
- Consistencia de Calidad: Al utilizar la pasarela para gestionar system prompts estandarizados y versiones de modelos específicas, se asegura que todo el contenido generado mantenga un tono de voz y una calidad uniformes, factores clave para la autoridad de dominio y la experiencia de usuario (UX).
- Experimentación A/B: Los equipos de SEO pueden probar diferentes modelos para ver cuál genera contenido con mejor rendimiento en SERPs (Search Engine Results Pages) y ajustar el enrutamiento en la pasarela para priorizar el modelo ganador.
Conclusión
La integración de la inteligencia artificial en el tejido empresarial ha superado la fase de novedad. Ahora, el reto es la gobernanza, la eficiencia y la seguridad. Una pasarela de IA para gestión de tráfico de modelos LLM no es una herramienta opcional para las empresas que buscan liderar su sector; es la infraestructura crítica que separa una implementación amateur de una operación profesional y escalable.
Centralizar el acceso a los modelos de lenguaje permite a las organizaciones recuperar el control sobre sus datos, optimizar drásticamente sus presupuestos operativos y garantizar una experiencia de usuario fluida y segura. En un entorno digital donde la agilidad y la fiabilidad son moneda de cambio, contar con una arquitectura de gestión de tráfico robusta es el cimiento necesario para construir el futuro de la empresa inteligente.